Depositing a dataset
- Creating a dataset
- Entering the first batch of metadata
- Adding the associated files to a dataset
- Saving a dataset
- Completing the metadata
- Indicate the terms of use for the dataset
- Managing the rights associated to datasets and files
- Case of blind peer-reviewed datasets
Creating a dataset
Please go to the collection you have identified (please see Identifying your depositing space in the Before depositing guide).
Click on Add Data > New Dataset
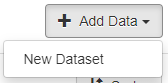
If the “Add data” button does not appear, please request posting rights from the administration team via the “Contact” button in the collection.
A collection may provide one or more templates in which some metadata, including the General Terms and Conditions and the licence, have been pre-filled in. If there is a suitable template this should be selected when creating a dataset as it cannot be applied retrospectively or changed.
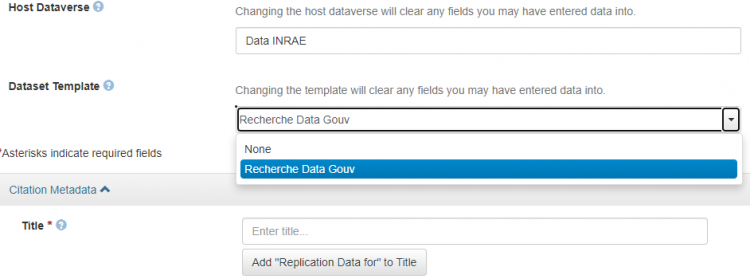
If the collection does not provide a template you can request one from the collection administrator using the Contact button.
Entering the first batch of metadata
Please enter the obligatory metadata which is marked with a red asterisk as well as the recommended metadata that is available when you create your dataset (it will be necessary to modify the dataset after saving to complete the metadata).
Please see the Guide to entering metadata.
 Entering the recommended metadata helps comply with the following principles: |
Adding the associated files to a dataset
One or more files can be associated with a dataset in the Recherche Data Gouv repository.
A file is also assigned its own DOI which is linked to the dataset's DOI. If the files have been deposited in another repository, the link to these will be given in the dedicated "Link to data" metadata.
All file types are accepted (tabular, text, pdf, image, video, audio, SHP, etc.). However, in the current context that favours data openness and reuse, it is strongly recommended to choose a format that is open or widely used and also machine readable.
 Using open formats complies with the Interoperable principle as such files can be read and modified using any software designed to process them (image, text, audio, etc.) |
Please see: A DoRANum ressource nammed : Open of Close Format ?
If the files have been deposited in a different repository to Recherche Data Gouv, please indicate the link to the data in the dedicated "Link to data" metadata.
Note: Files can still be added after the dataset has been saved or published.
Click on Select Files to Add or drag and drop the file(s).
All file formats are accepted.
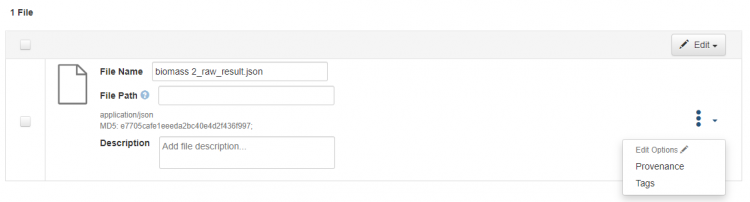
Fill in the specific metadata for the file:
- File name: auto-filled, can be modified
- File Path if necessary
- Description
- Tags. There are three default labels: Data, Documentation and Code.
- Provenance
The media type (MIME type) of the file will be recognized even if the file has no extension. The Dataverse software may propose a preview of the file depending on its type.
The maximum size for each file uploaded is 50 GB.
It is recommanded to upload a maximum batch of 200 files in one transfer via the user interface. If you have more files than that, you must use the DVUploader tool and the Direct Upload Dataverse API.
When files are uploaded to a dataset, they are assigned:
- a digital fingerprint enabling the integrity of the data (no corruption of the file) to be checked: UNF for tabulated files, MD5 for other formats (please see the footnotes);
- a DOI.
For more information regarding large amount of files deposited and datasets' sizes, please refer to "Recommandations on large datasets"
Tabulated data files
The Dataverse software integrates xlsx (Excel), csv, tsv, R data, SPSS and Stata files as a tabulated .tab file (open format). The original format also remains available for download.
Note: Only tabular data files that are smaller than 500 MB are transformed into .tab files.
The file is analysed by the Dataverse software during the upload and the message “Chargement en cours” ("Loading in progress") is displayed:
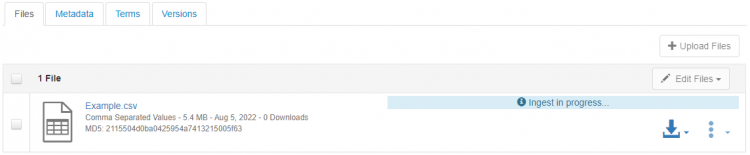
When the upload is complete, the message "The operation has succeeded! - The tabular files have been uploaded" is displayed and a message is sent to the depositor ("Your ingest has successfully finished!").
The numbers of variables and observations are displayed in the file metadata:

It is strongly advised to verify those informations are correct !
If the file couldn't be analysed by the Dataverse software, an error signal is displayed yet the file is imported in its original format.

The Dataverse software will send a mail entitled “Your ingest has finished with errors!” to the depositor. The type of error is not indicated.
Conditions for the effective ingestion of tabulated data
- General recommendations
- UTF-8 encoding for files containing special characters,
- no empty headers or missing cells (see table below; empty cells are accepted),
- each column header must have a different name,
- if your file contains more than 1024 columns, it will be submitted but cannot be ingested,
- no line break in a cell.
- If the file is in Microsoft Excel format
- each Excel file must contain only one tab/sheet, with the variables on the first line (column headers) and one observation per line.
Warning! if there are several tabs, only the first one is ingested by the Dataverse software and will be taken into account in the display, exploration and export in tabulated format, - no merged cells,
- no legend,
- To help identify errors in an Excel file, one solution is to open the xlsx file with LibreOffice Calc and save it as a .csv file with UTF-8 encoding. See the procedure for Ingesting csv files
- each Excel file must contain only one tab/sheet, with the variables on the first line (column headers) and one observation per line.
- If the file is in csv format
- use the comma as a separator (the semicolon is not accepted by Dataverse software),
- the decimal separator must be the full stop (otherwise commas will be understood as separators),
- in text cells containing commas, the text must be enclosed in inverted commas (otherwise the commas will be understood as separators).
example of a csv file with an error: | example of a csv file without errors: ColA,ColB,ColC 1, ,3 4,5,6 |
example of a Excel file with an error: 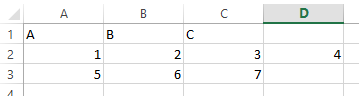 | example of a Excel file without an error: 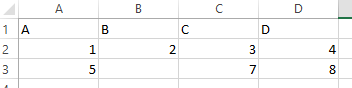 |
Also see: Broman, K. W., & Woo, K. H. (2018). Data Organization in Spreadsheets. The American Statistician, 72(1), 210. https://doi.org/10.1080/00031305.2017.1375989
Please see: Tabular Data File Ingest to find out more about the processing of tabulated data by the Dataverse software.
NB : the cheat sheet Ingesting csv files details the steps for converting to UTF8 encoding and defining the comma as the value separator for a CSV using LibreOffice CALC software.
Saving a dataset
Click on Save Changes.
The dataset will be given provisional unpublished status.
A DOI will be reserved and activated when the dataset is published.
Completing the metadata
When a dataset is created, only a limited amount of metadata is visible and can be filled in. To complete and enrich the metadata description of the dataset, this must be modified after the first time it is saved.
Metadata can be edited on the dataset display page accessed via the menu Edit Dataset > Metadata
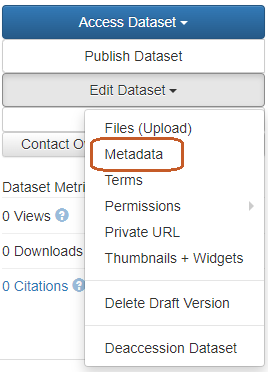
or via the tab Metadata > Add + Edit Metadata.
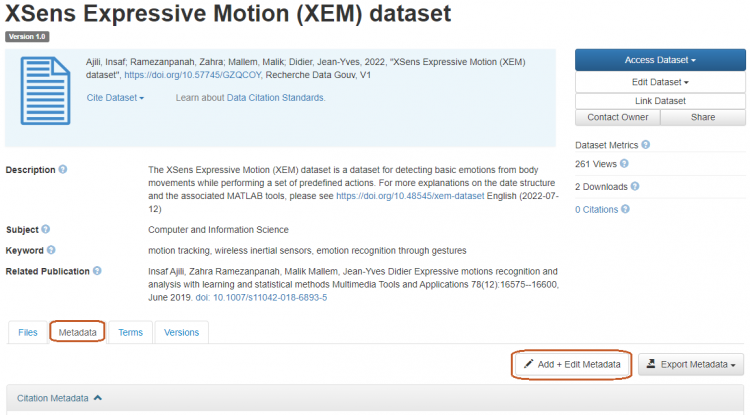
Please refer to the Guide to entering metadata to find out about the metadata that needs to be entered.
Indicate the terms of use for the dataset
The following can be specified in the terms of use:
- the licence assigned to the dataset,
- the conditions for access to restricted files,
- the existence of a guestbook.
These conditions apply to all the dataset's files.
The terms and conditions of use are available on the dataset's display page via this menu - Edit Dataset > Terms.
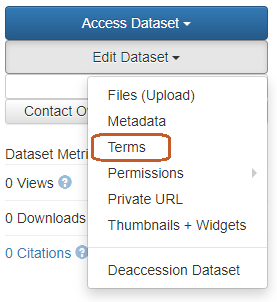
or via the Terms > Edit Terms Requirements tab.

Licences
Note: it is not possible to assign different licences to different files within the same dataset.
Open licenses Etatlab 2.0 is the default licence assigned to a dataset by the Dataverse software. To assign one or more other licences to the data, go to the Conditions tab:
- select “Custom Dataset Terms”;
- enter your chosen licence(s) in the Terms of use metadata.
- For example, here is the code for Creative Commons CC- by 4.0:
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Licence Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a><br />This work is made available under the terms of <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Licence Creative Commons Attribution 4.0 International</> - It is possible to specify the data file to which they apply.

Please see: the list of licences that can be used that comply with the Law for a Digital Republic (more information in the Application Guide for the Law for a Digital Republic of the French Open Science Committee).
Note: It is recommended that software should be accompanied by a licence file.
The terms of use, and more specifically the licence, can be pre-entered in a template provided by the collection in which the dataset is to be created. If you are in doubt about this, please ask the contact person or the collection administrator.
If the dataset re-uses existing data, you should ensure the licences are compatible (e.g. the "SA" condition in a CC-BY-SA licence).
 Assigning a licence to the dataset respects the Reusable principle by making clear the conditions for the reuse of data. |
Conditions for restricted access files
These set out the access conditions for files with restricted access.
Please see: restricting access to a data file to find out how to do this
The guestbook
The guestbook serves to collect information from users who display, browse or download a file from the dataset which the log applies to. The depositor is responsible for associating a guestbook with a dataset. However, the collection administrator can create a guestbook and view the data collected there.
A collection does not have to include a guestbook.
To apply a guestbook to a dataset:
via the tab Terms > Edit Terms Requirements > Guestbook
or via the command Edt Dataset > Terms > Guestbook
Note: the data in guestbook are deleted after a year.
Managing the rights associated to datasets and files
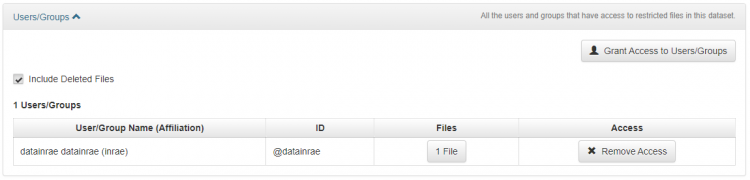
As long as the dataset remains unpublished, only the authorised persons can access it namely by default the depositor, the administrator and curator(s) of the parent collection. Additional authorisations can be granted at the dataset level to assign roles to users or groups.
Rights associated to datasets and files
Roles Permissions associated to the role | Admin | Curator | Contributor | Member | File Downloader |
| Download file | + | + | + | + | + |
| View unpublished dataset | + | + | + | + | |
| Edit dataset | + | + | + | ||
| Delete dataset draft | + | + | + | ||
| Publish dataset | + | + | |||
| Manage dataset permissions | + | + |
Assigning a role to a dataset
As the table above shows, only curators and administrators of a dataset can manage authorisations for that dataset. The dataset's creator may have the role of curator or collaborator depending on the current settings in the collection in which the dataset was created. The creator can therefore only assign a role to a user or group if s/he is a curator of her or his dataset.
Edit Dataset > Permissions > Dataset
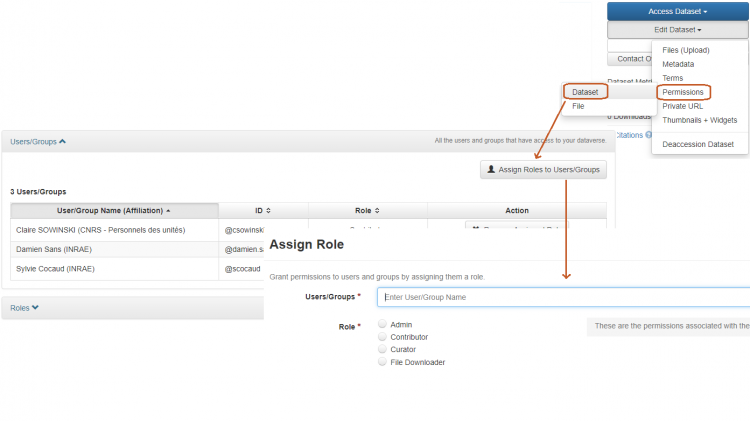
Restricting access to a data file
Access to a data file can be restricted by its depositor or any person authorised to modify the corresponding data set.
Edit Files > Restrict
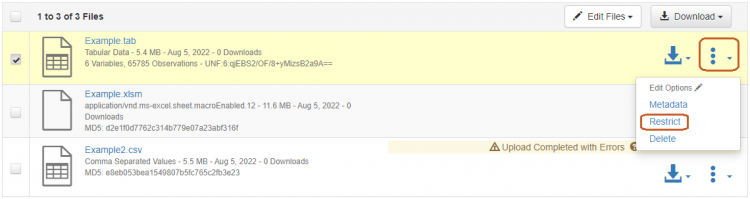
Indicate the access conditions and choose whether to check the box enabling people to request access to the file by e-mail.
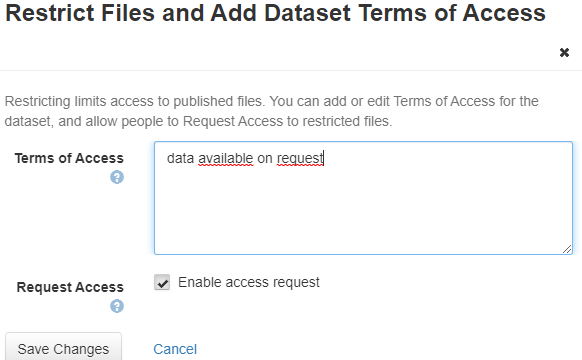
The access conditions can also be modified via the command Edit dataset > Terms
Note: the access conditions cover all the files in a dataset.
- If the depositor does not check the "Request access" box only authorised users will be able to download the file. Other users will not be able to request access to the file.
- If the depositor checks "the "Request access" box to the file can be requested:

The person wishing to make the request will have to log in to do so.
If the depositor is also the curator of the dataset, s/he will receive an access request e-mail (subject: “Recherche Data Gouv: "You have a request to access a file with restricted access" containing a link to manage access to the file and is notified of this request (again with a link to manage access to the file).
If the depositor is a collaborator, the collection administrator or curator will receive and process the access request.
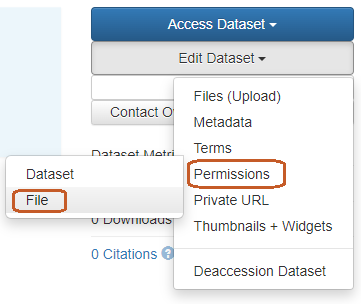
The access request can be approved or rejected by clicking on the link received in the e-mail and in the notification or by going directly to the dataset menu:
Edit dataset > Permissions > File
If the request is accepted, the sender will receive an e-mail and a notification in her/his personal space and can then download the file.
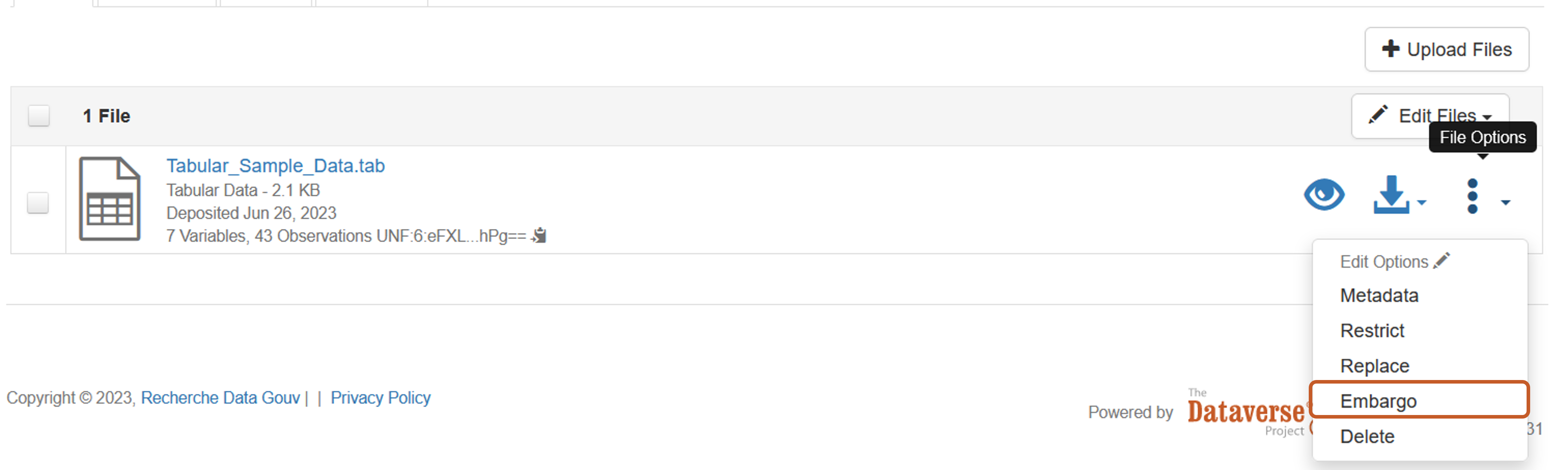
Applying an embargo to a data file
It is possible to apply an embargo to a data file if a "proprietary" period on the data is recommended or is in accordance with the best practices of a community. The maximum embargo period in the Recherche Data Gouv repository is set at 18 months. The embargo cannot be modified or removed once the dataset has been published. It will automatically end at the specified date. Once the embargo has expired, the files become accessible. If restrictions have been applied, these apply in the same way as for files that have not been embargoed.

Giving access to an unpublished dataset (private URL)
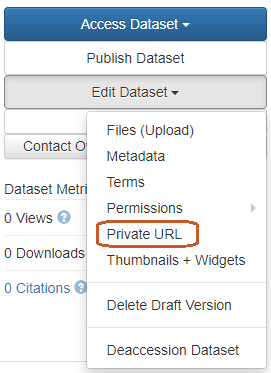
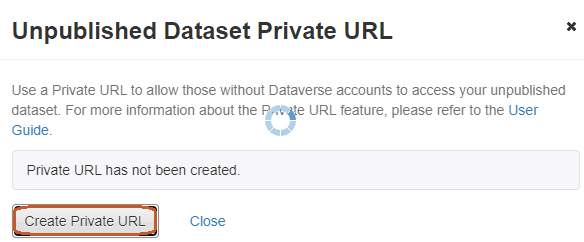
If the depositor is a curator of the dataset, s/he can generate a private URL to give access to an unpublished dataset to a person who does not have an account in Recherche Data Gouv's platform.
If the depositor does not have access to this function, s/he can ask the curator or administrator of the host collection to generate the private URL on their behalf.
This function can be useful, for example to give access to reviewers of an accepted article who are asking to see the data associated to the article without having to send the data or make them public.
Edit Dataset > Private URL
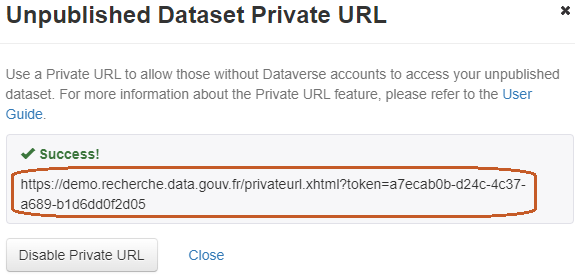
Note: A private URL is temporary and is deactivated when the dataset is published. The private URL should therefore not be displayed in the article. If a private URL is sent to the reviewers of an article being submitted, it is preferable to wait until the end of the peer review process before publishing so that the reviewers do not have any problems accessing the dataset.
Giving access to an unpublished dataset (URL for anonymized access)
In cases where datasets are to be blind peer-reviewed, it is possible to create a private URL for anonymized access, as shown in the figure below. By doing this a pre-established list of metadata (author, dataset contact, contributor, productor, publications, grantID, Project information, Related dataset) will be anonymised.
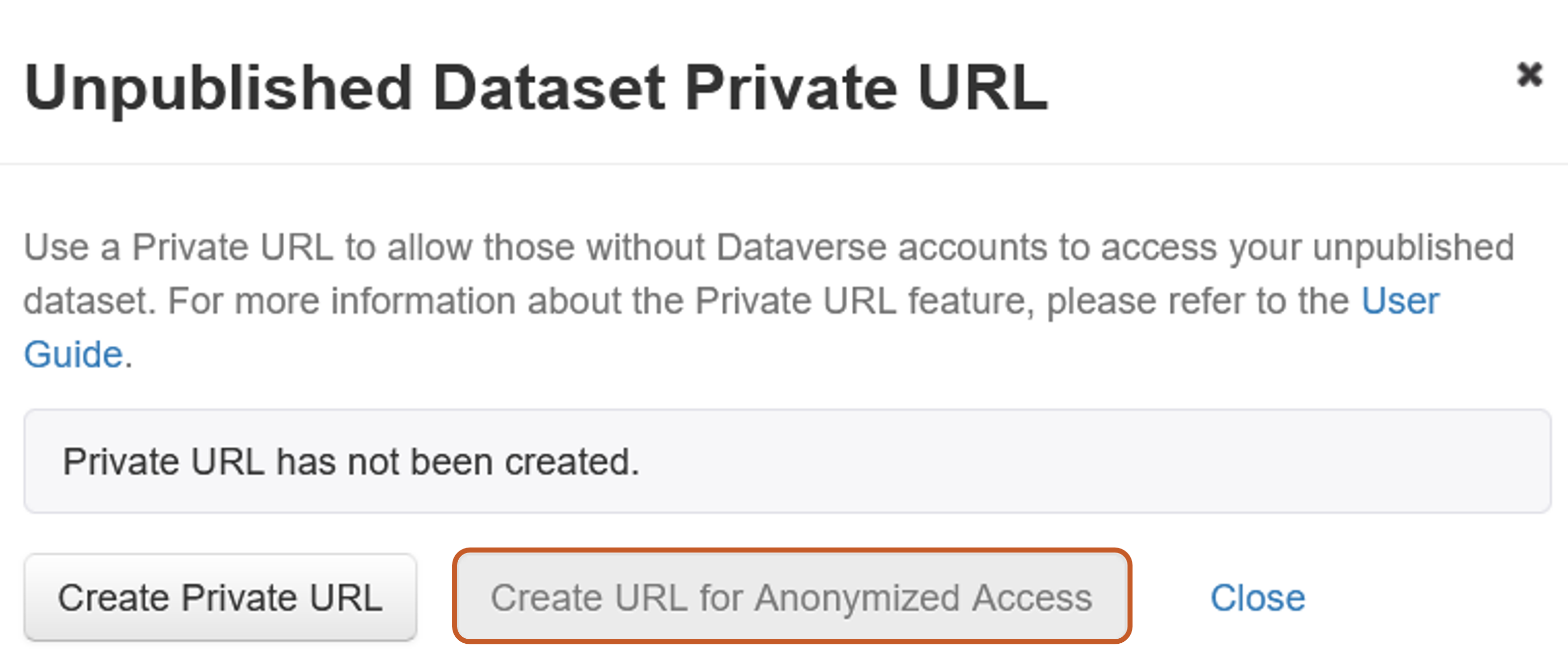
However, as the list of anonymised metadata is pre-defined and cannot be customised, we recommend that you follow the procedure explained in the section Case of blind peer-reviewed datasets.
Case of blind peer-reviewed datasets
When datasets are to be reviewed anonymously by peers, they are subject to a special deposit procedure. They are not initially deposited in the target collection in order not to disseminate information allowing identification of the author.
A fictional (unpublished) collection has been created for this purpose. Here is the procedure for these datasets:
- Author sends an email to the Repository-Registry Resource Centre to request the creation of a dataset with anonymized identifying metadata
- Information to transmit:
- Dataset title
- Target collection name
- The Repository-Registry Resource Centre creates the dataset by applying a data model and gives the contributor role for that dataset to the author.
- The author completes the metadata, adds the files.
- The author sends the dataset for review. A private URL for anonymized access, for peer communication, is sent back.
- Once the publication has been accepted, the depositor contacts the Repository-Registry Resource Centre, which takes care of moving it to the target collection.
- The author updates the anonymized values and completes the metadata in the target collection if necessary.
______
Notes
[1] UNF: a small string of alphanumeric characters of fixed length which summarises a data set's content. Any changes to the data results in a new universal digital signature no matter how minor the change. The UNF ensures that the file is not corrupted.
[2] The MD5 or Message Digest 5 algorithm is a hash function that provides a digital fingerprint of a file so that the integrity of a downloaded file can be checked.